
Dans le monde scientifique, le fameux diktat “Publish or Perish!” est toujours aussi puissant et il continue de contribuer à une production sans précédent d’articles scientifiques. Cette course à la publication n’est pas sans lien avec l’impression partagée par de plus en plus de gens que tous ces articles scientifiques pourraient ne pas être originaux. Grâce à des logiciels de détection, il est désormais possible de mesurer le degré de similitude entre des millions d’articles. Plusieurs études ont confirmé cette impression de non-originalité.
Par exemple, Harold Garner, un chercheur de la University of Texas Southwestern Medical Center à Dallas, a utilisé eTBLAST (un outil de détection de similitudes) pour étudier un échantillon de titres et résumés d’articles de la banque de données Medline. Voici une idée des résultats:
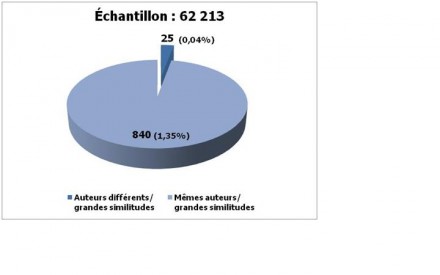
Les résultats de cette étude ont fait l’objet d’un article dans la revue Bioinformatics (Vol. 24, no. 2, 2008, pages 243-249) intitulé “Déjà vu – A study of duplicate citations in Medline“. (Cliquez sur Full Text dans le menu de droite pour obtenir l’article complet.)
Le problème n’est pas nouveau! En effet, il y a seize ans plus tôt, en 1993, Serge Larivée publiait La science au-dessus de tout soupçon, aux Éditions du Méridien. Il y abordait en détail la fraude scientifique dont le plagiat, l’auto-plagiat, les différentes formes de publications (salami, rapide, incomplètes…), les soumissions multiples. L’auteur fait un bilan de la fraude scientifique depuis ses origines jusqu’à son traitement, en passant par ses formes, sa détection. Un ouvrage à lire absolument !





